2024-10-04
Transformers and So On
On my journey to understand the AI architectures shaping our future, I found myself captivated by the transformer model. It's no surprise, given how Large Language Models (LLMs) have surged in popularity since the release of GPT-3, making knowledge more accessible than ever. Now, you can ask any question, anytime, anywhere - no more waiting for a teacher's response or wondering if they'll know the topic.
This piece assumes a basic understanding of neural networks and aims to guide you through the inner workings of the transformer model, helping you develop an intuition for how it all comes together. Just as these models process and make sense of language, we'll explore the steps that make transformer so revolutionary.
Part 1: Attention Mechanism
The transformer's core is the attention mechanism, which drives its ability to handle complex language tasks—from translation to conversation—by allowing the model to focus on the most relevant parts of a sequence. It works much like how we emphasize key words in a sentence.
The model takes an input, applies a series of transformations, and produces an output. We first convert words into embeddings, which are mathematical vectors that capture their meaning in a latent space. These numerical representations enable the model to process text mathematically.
There are several methods for creating these embeddings, such as Word2Vec or BERT-based embeddings, but for our purpose here, we’ll assume they’re already in place.
Transformers process the entire input sentence simultaneously, unlike traditional RNNs that handle words one at a time. To retain the order of words ('cat ate a fish' vs. 'fish ate a cat'), we introduce positional encoding. This technique gives each word a sense of its position in the sequence, which is added to its embedding, ensuring the model can distinguish between different word orders.
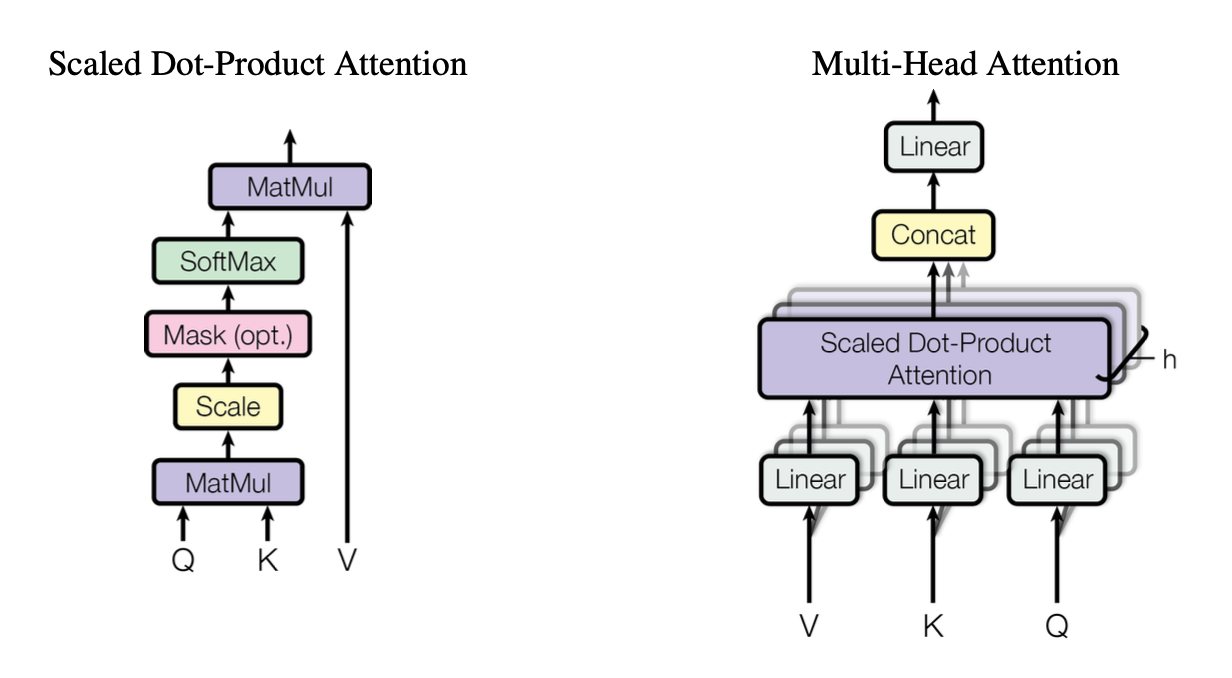
Once the input is prepared, the model generates three vectors for each word: a Query (Q), a Key (K), and a Value (V).
- The Query can be thought of as "what this word is looking for."
- The Key represents "what this word signifies."
- The Value contains "the information the word carries."
Multiple sets of these vectors, known as multi-head attention, allow the model to focus on various aspects of the input, such as grammatical structure or long-term dependencies.
Why do we need multiple heads? Well, each head can focus on different parts of the input, like a group of friends each noticing different details in a story.
 Single vs. Multi-Head Attention: Multi-head attention allows the model to capture different aspects of the input simultaneously, enhancing its ability to focus on various features.
Single vs. Multi-Head Attention: Multi-head attention allows the model to capture different aspects of the input simultaneously, enhancing its ability to focus on various features.
Step 1: Calculating Attention Scores (Dot Product of Query and Key)
To find the relevance of each word in relation to others, we compute the dot product between the Query and Key vectors. A higher dot product indicates a stronger relationship, as vectors pointing in the same direction result in a larger product.
These scores help the model identify the most important words, like highlighting "fish" and "ate" in "the cat ate the fish" to understand the action.
Step 2: Scaling and Applying Softmax
Next, we scale these scores (just a fancy way of keeping them balanced) by dividing them by the square root of the Key dimension. Then, we apply the softmax function to turn these scores into probabilities, which highlight the most relevant words in the context.
Step 3: Computing the Weighted Sum (Using Value Vectors)
Finally, we use these probabilities to blend the Value vectors. This step "updates" each word's understanding based on its context, like refining a summary that's now packed with the key points.
In summary, the attention mechanism refines each word’s embedding based on its relation to others, enabling the model to learn which parts of the input are most relevant.
Part 2: Transformer Architecture
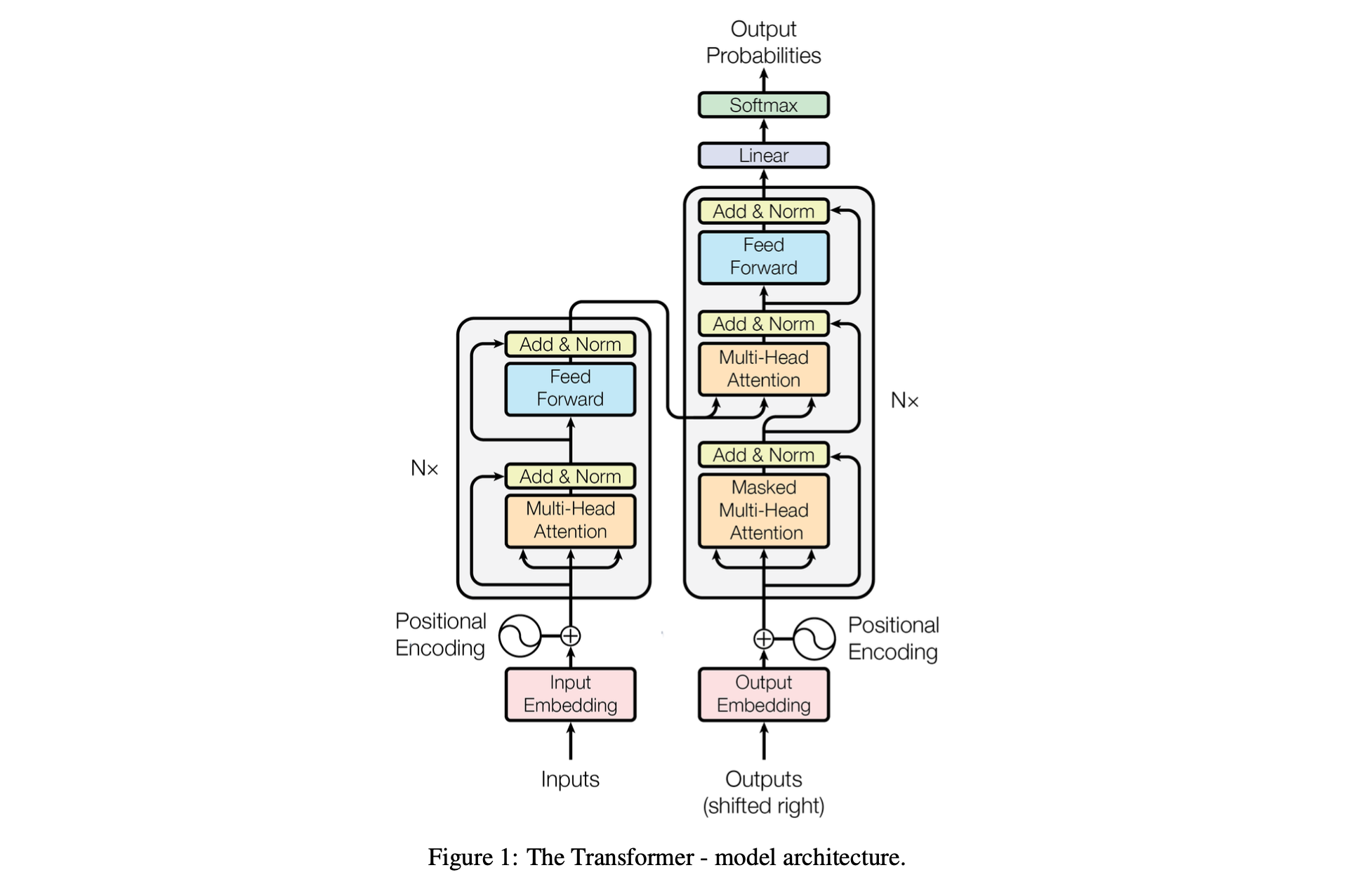 The Transformer Architecture: Composed of an encoder and a decoder, each built upon multiple layers of attention mechanisms and feedforward networks.
The Transformer Architecture: Composed of an encoder and a decoder, each built upon multiple layers of attention mechanisms and feedforward networks.
The transformer is built upon the attention mechanism and consists of two main components: the encoder and the decoder. The encoder processes and understands the input, while the decoder generates the output, guided by the encoded information and its previous outputs.
1. The Encoder: Understanding the Input
Overview: The encoder is responsible for processing and understanding the input text. It extends the attention mechanism we discussed earlier, adding multiple layers to deepen its understanding.
a. Input Embeddings and Positional Encoding
The encoder transforms each word into an embedding. Since it processes the entire sequence in parallel, it uses positional encodings1 to distinguish word order, adding context to the embeddings.
b. Self-Attention Mechanism
Next, the encoder applies the self-attention mechanism. Self-attention allows the model to consider the relationships between all words in the sentence simultaneously. This bidirectional approach is like reading a sentence while keeping both the beginning and end in mind.
For example, self-attention lets the model focus on "ate" while understanding the significance of "hungry" earlier in "The cat, which was hungry, ate the fish." Unlike traditional models that look at words sequentially, self-attention captures dependencies from both previous and future words. This allows the model to understand complex language structures, enriching each word's contextual representation.
c. Feedforward Neural Network and Residual Connections
After self-attention, the encoder processes each word independently through a feedforward neural network. This network further refines the representation of each word based on the context provided by self-attention.
Additionally, each self-attention and feedforward step includes a residual connection—where the input to each layer is added to its output—to help the model maintain information from previous layers and prevent degradation. Layer normalization is also applied to stabilize and speed up training.
d. Stacking Multiple Encoder Layers
This process of self-attention, followed by the feedforward neural network, is repeated across multiple layers in the encoder. Each layer acts like an editor refining a draft. As the model passes through more layers, its understanding deepens, capturing subtle language nuances and building on previous layers.
2. The Decoder: Generating the Output
Overview: The decoder generates the output sequence one word at a time, using the encoded information from the encoder and its own previously generated words.
a. Masked Self-Attention: Generating Output Word-by-Word
The decoder receives the previously generated words as input and applies masked self-attention to ensure it only considers words up to the current point. Masking prevents the model from "seeing" future words during training, simulating how text is generated sequentially.
This allows the model to predict the next word based solely on what has already been generated.
b. Cross-Attention: Focusing on the Encoded Input
The decoder also employs cross-attention, which allows it to focus on relevant parts of the input sequence processed by the encoder. It uses the current state of the decoder to generate queries and compares them against the encoder's keys to produce an attention score.
This score guides the model in deciding which encoded words are most relevant for generating the next word in the sequence.
c. Feedforward Network and Stacked Decoder Layers
After the cross-attention step, the decoder refines the word representations using a feedforward neural network. Similar to the encoder, the decoder consists of multiple layers, each including masked self-attention, cross-attention, and a feedforward network, along with residual connections and layer normalization.
This iterative process fine-tunes the output word-by-word.
3. Output Generation
Finally, the decoder's output is passed through a linear layer and a softmax function, which converts the final vector into probabilities for each possible word in the vocabulary. The word with the highest probability is selected as the next word in the sequence.
This process repeats for each new word until the model generates the complete output or encounters an end-of-sequence token.
In summary, the encoder and decoder work together to form the backbone of the transformer architecture. The encoder builds a rich representation of the input, while the decoder uses this representation to generate coherent and contextually relevant outputs. This combination allows transformers to excel in a variety of natural language processing tasks, from translation to summarization.
Part 3: Variants (Encoder/Decoder Only)
Now that we've covered the full transformer, let's look at its variants. Sometimes, we only need one part of the transformer—the encoder or the decoder. Here's where things get interesting!
1. Encoder-Only Models (e.g., BERT)
Overview: Encoder-only models, such as BERT (Bidirectional Encoder Representations from Transformers), use only the encoder component of the transformer. They are designed to create a detailed, context-aware representation of the input by leveraging the self-attention mechanism across multiple layers.
How They Work: These models process the input text using self-attention to understand the relationships between all words in the sequence. A key feature of encoder-only models like BERT is their bidirectional context; they consider both the left and right surroundings of each word, enriching each token's representation with information from the entire input sequence.
This bidirectional approach is like reading a paragraph before interpreting a single word, allowing BERT to grasp nuanced meanings for tasks like sentiment analysis.
Training: BERT is trained using a masked language model (MLM) objective, where some words in a sentence are masked, and the model learns to predict these missing words. This bidirectional training approach enables the model to develop a deep understanding of language patterns and nuances.
Strengths and Use Cases: Encoder-only models are particularly effective for tasks requiring a comprehensive understanding of the input, such as sentiment analysis, named entity recognition, and question-answering. However, they are not typically used for text generation since they focus solely on interpreting the input.
2. Decoder-Only Models (e.g., GPT)
Overview: Decoder-only models, like GPT (Generative Pre-trained Transformer), use just the decoder component. They are tailored for generating text sequences by predicting each next word based on the previous ones, making them suitable for tasks like text generation and conversational AI.
How They Work: These models process input text sequentially, using masked self-attention to ensure that each word prediction depends only on previously generated words. It's like writing a story: each new word depends on those before it, ensuring coherence as the narrative unfolds.
This sequential, left-to-right approach simulates natural language generation, enabling the model to continue generating text until it encounters an end-of-sequence token.
Training: Decoder-only models are trained using a causal language modeling (CLM) objective, where the model learns to predict the next word in a sentence. During training, it is exposed to vast amounts of text, learning to generate coherent sentences that align with the input context.
Strengths and Use Cases: Decoder-only models excel in text generation tasks, such as essay writing, completing prompts, and generating responses in chatbots. Their autoregressive nature—predicting each word based on the prior context—makes them ideal for creative writing, interactive applications, and dialogue generation.
In summary, encoder-only models like BERT focus on building a deep, bidirectional understanding of the input, making them ideal for comprehension-focused tasks. Decoder-only models like GPT, in contrast, excel at sequential text generation, leveraging unidirectional context to predict the next word. Each variant is optimized for different challenges within natural language processing.
Closing Thought
I hope this blog has deepened your intuition and helped you better understand how transformers work under the hood. Transformers were revolutionary when they first appeared, not just because of their catchy name, but due to their novel use of the attention mechanism, setting them apart from previous models.
When "Attention is All You Need" was published in 2017 by Ashish Vaswani and others, the research community took notice. However, few could have predicted just how transformative this architecture would become. Visionaries in AI, like Ilya Sutskever and the teams at OpenAI, recognized its potential and took the bold step of scaling these models to unprecedented levels. At the time, many believed that achieving intelligence required entirely new architectures. Yet here we are: models like GPT-4 have surpassed the Turing test, demonstrating interactions that are strikingly human-like.
The debate continues about whether these models genuinely "understand" language or merely generate responses by leveraging vast amounts of training data. My perspective aligns with Geoffrey Hinton, often referred to as the "Godfather of AI." He suggests that while modern language models may not possess experiential knowledge, they develop internal representations of language, recognizing patterns and context in ways that mirror human processing. This blurs the line between mere pattern recognition and something more akin to understanding.
Now that you've explored the structure of transformers, what do you think? Are they simply intricate pattern matchers, or is there a hint of deeper intelligence at play? The answer may not be straightforward, but it is certainly a question worth pondering.
Footnotes
-
For those interested in a deeper dive, positional embeddings can be categorized into deterministic and learnable, but here we'll focus on deterministic sinusoidal embeddings, which was originally proposed in the seminal paper "Attention is All You Need." These embeddings are not learned during training but are instead computed using sine and cosine functions with varying frequencies to present positions.
For a given position (ranging from 0 to ) and an embedding dimension (ranging from 0 to ), the sinusoidal positional embedding can be mathematically described as:
Where:
- Even indices () use the sine function
- Odd indices () use the cosine function
- The denominator scales the position, allowing the model to capture both short- and long-term dependencies. The constant 10000 is a hyperparameter, chosen to ensure the embeddings work well across different sequence lengths.
Key Advantages of Sinusoidal Embeddings:
- Unique Representation: Each position receives a unique embedding, thanks to the alternating sine and cosine values.
- Smoothness: Nearby positions have similar embeddings, helping the model learn relative positions.
- Extrapolation: The periodic nature of sine and cosine allows the model to extrapolate to positions beyond the maximum trained context, although with limitations.
- No Extra Parameters: Since these embeddings are deterministic, they don't add any additional parameters to the model.
Context Length and Model Limits The maximum sequence length that a model can handle is directly related to the positional embeddings. Let represent the set of positional embeddings defined for position 1 through . The model's context length is simply:
Where:
The context length defines the maximum input size the model can process at once. If input exceeds , the model truncates and ignores the extra tokens.
Why Not Extend for Infinite Context? while sinusoidal embeddings allow for some extrapolation, setting a maximum sequence length is crucial for several reasons:
-
Efficiency of Training and Computation:
- Quadratic Complexity: The self-attention mechanism computes interactions between every pair of tokens in a sequence, which results in a computational complexity of O(). As increases, both the computation of and memory requirements grow quadratically, making long sequences highly inefficient.
- Memory Constrains: Transformers store large attention matrices of size , consuming significant GPU/TPU memory. This imposes practical limits on the sequence length due to hardware constrains.
-
Extrapolation Challenges:
- While sinusoidal embeddings enable some degree of extrapolation beyond , this isn't perfect. As the sequence grows, positional embeddings for distant positions start to resemble each other due to periodicity of sine and cosine functions. This can lead to reduce accuracy in handling long sequences.
-
Generalization and Overfitting
- Training Data Distribution: If a model is trained on sequence of length , its ability to generalize to much longer sequences is limited. The model may not have learned to manage dependencies over such long ranges, leading to poor performance.
- Long-Range Dependencies: While transformers handle short- and medium-range dependencies effectively, long-range dependencies (e.g., across hundreds or thoudands of tokens) pose significant challenges. Specialized architecture like Longformer or Transformer-XL are designed to handle longer sequences by focusing on the issue.